
電話番号 : 13486085502
June 29, 2020
それはAppleがIntel x86プロセッサからのMacコンピュータの自身の腕ベースの破片にスイッチの始めを発表したので腕のための巨大な週、だけでなく、であり。はじめて歴史で、世界で最も速いスーパーコンピュータが腕の破片によって動力を与えられることを非営利高速・大容量の演算ランク付け構成Top500はまた今週発表した。
今週発表されるデータ センタの腕のための2つのより大きい開発を加えなさい。おそらく今では知っているように、クーラーを作り出す競争はIntelの共同出資者のゴードン・ムーアの法律からそしてソフィー・ウィルソンの夢の方により有効なサーバー回転を取り去った。128中心のAltra最高プロセッサの見本抽出が第四四半期で始まることをちょうど3月に80中心のAltraの腕CPUを進水させたこと計算するサンタのクララ ベースのアンペア元Intelの大統領がReneeジェームス形作った腕サーバー破片の開始は、発表した。hyperscaleの雲の提供者に方形に焦点を合わせられて、アンペアはIntelのXeonプラチナ8160 ($9,899提案されたリスト)および性能のAMDのEpyc 7742 ($6,950)と競うように部品を設計した。
また今週、Kaleaoとして去年までおよびタケ システムとして再構成されたこの前12月は知られていたケンブリッジ、イギリス基盤の会社言った最初1U腕サーバー、第三四半期のB1000Nシリーズを、解放することを。サーバーは端のデータ センタのようなローパワー環境のために、設計されている。
私達の自身の計算によるデータ センタの腕プロセッサの建築の「出現」は第5年によく既にある。それほど現代データ センタの建築そして構造について直接的または間接的に建築がPCのために最初に作成したx86プロセッサから得た。しかしずっとこのスペースの腕の進化は遅い安定している。
最高スーパーコンピュータの領域のためにアンペアの新しい128中心Altraの性能は向けている。そこでは、IntelのXeonプラチナ8160の力最も最近のTop500の9つのシステム。
「high-levelで、私達はIntelが每CPU基礎に」とあるよりより多くの性能をそれほど提供しているジェフWittich、プロダクトのためのアンペアの年長VPは、言った。未加工数はまだないが、Wittichは同じようなx86プロセッサに対して2.2x性能の利益を要求して、新しい部分をに対して比較するアンペアの選択のIntelの破片はずっと8160である。
最高Altraは最も高い腕の中心の計算を要求した80中心Altraとソケット互換性がある。Wittichは128中心プロセッサが性能每中心が中心の計算の増加として次第に落ちないことを意味する線形スケーラビリティを維持することを主張した。

2019年5月以来の歓迎された開発である彼の要求が当てはまれば。調査で最初の腕ベースのスーパーコンピュータはそれからだったものの月[PDF]、ブリストル大学のチームが1つを含む同じような指定と28中心のXeonプラチナで8176台のプロセッサを造られたCray機械に対して性能を、システムがIsambardをダビングし、Marvell ThunderX2の腕プロセッサによって動力を与えられたCray XC50の偵察者、比較したこと出版した。
ブリストルのチームはMarvellの破片が効率の断崖の計量に苦しんだことが、特に分った16のノード計算の後で。64のサーバー ノードで、腕ベースのプロセッサのための効率を量ることは80%の下でIntelの破片は100%の上に完全にとどまったが、落ちた。
アンペアのテストは中心および糸の計算ノード計算ではなくに対照的に基づいている。どんなWittichが言ったか本当を証明したらまだ、それは意味する武装するプロセッサ エンジニアは彼らのプロダクトをHPCスペースで非競争的したかもしれない深刻な故障を克服した。
「私達の焦点ずっと雲である、従って私達は私達の雲の環境のためのすべてを最大限に活用している」、はWittichはDCKを言った。「しかし私達がそこにしている多くの事は拡大縮小が可能なスーパーコンピュータに同様に適用できる。従って私達は興味を確かにそこに見る。それを」。排除する何もない
アンペアは中間2021によって一般的な大量生産に最高Altraを持って来ることを向ける。
「多くの会社はサーバーにそこに既に腕プロセッサを入れている。HPEに、Supermicro、Lenovoすべて得られた1つがある」、トニーCraythorne、タケ システムのCEOは、気づいた。「しかししたすべてはx86建築に文字通り腕の破片差し込まれる。それは腕の利点のいくつかを与えることができる—それは力および冷却を減らす—しかしそれは処理、入力/出力および腕に大きい利点が」。ある効率の機能の利点の与えない、
プロセッサのこの様式のまわりで造られた彼のポイントはタケが腕によって代わりになったIntelまたはAMDプロセッサが付いているちょうどサーバーを導入していた全く新しい建築ことだった。名前が制作された努力の一部を示して、彼はそれ平行腕のノードによって設計されている建築と、またはパンダを呼ぶ。
「私達のプロダクト最低(およびそれでの50%までエネルギー消費の75%今日顧客を取得原価より高く行くことができる)救うことができ、私達が非常に小さい形式要素に得てもいいこと密度による棚スペースの約80%」はCraythorneはDCKを言った。
彼が「ミニ スーパーコンピュータ」のスケーラビリティと呼んだことをのためにタケ建築が設計されているが、少なくとも低価格からの開始を量るこの初期で。各々のタケ サーバー ノードは4つの完全な演算処理装置を含んでいて各刃が1-2の刃を、含むかもしれない。1U箱は8つのLinuxサーバー、熱心な記憶とのそれぞれおよび貯蔵を含んでいる。4Uプロダクトを年内に作り出すタケ計画。
「理由の一部分私達は1Uとしてそれを進水させている[ある]この技術は新しい」とことを私達が理解するCraythorneは言った。「皆はIntelのレガシー システムがある。それを投げ出し、4Uシステムに$150-200,000を使うことを行くことをちょうど行っているだれも。それらはちょうどそれを試みたいと思う場合もある。それらは買い易い何かが、低価格試すために販売すること容易ほしいと思う、従ってそれから」。それらのために働く筈だかどうか見ることができる
「安価によって」Craythorneは$9,995を意味した。典型的な1Uローパワーx86サーバーが販売できる間、以下$1,500のためにそれぞれは「ノード」単一のクォード中心CPUしか含まないかもしれない。タケCEOは容量の16kWを合計する8つの2U Dell PowerEdge R740XDサーバーの棚を作動させる3年の費用を推定するのに彼のチームがAWSの所有権の計算機の総額を使用したことを私達に言った。AWSの3年TCOの見積もりはおよそ$560,000だった。
タケがまだ実質の3年の試運転を支えるために持っているが、会社はB1008Nサーバーの同様に実行棚を負う同じ期間にわたっての約$200,000を要求する。
タケの投射を比較するため腕サーバーのための少数のTCOの調査がある。Hewlett-Packard (今HPE)の最初64ビットARMv8サーバー カートリッジの2014年分析、分析者パトリックMoorhead [PDF]によるProLiant M400は、少なくとも先例を置くかもしれない。M400が1Uよりもむしろ「カートリッジ」だったが、Webサーバのシナリオで使用されたとき、MoorheadはM400の3年TCOが同様に実行1U x86サーバーのTCOより低い35%ことを写し出した。Moorheadの研究はSandiaの国立研究所からの入力を含んでいた。
CraythorneはB1008Nが顧客を取得原価救うことができる50%までこと棚スペースのエネルギー消費の少なくとも75%、および80%主張したより高いサーバー密度のために。彼が言ったが彼の会社は内部テストを行ない、それらのテストを示す作り出されたグラフは公に知られていた基準を含んだ、タケはまだ堅い数を解放するために持っているが、Craythorneは言ったそう近い将来にすることを。
彼はまたx86が腕で動くことができるようにタケTCOのその部分が最初に設計されているある適用のリコンパイルに使うことができることを是認した。
あらゆる腕プロセッサはSoftbankのグループ所有のアームホールディングスから認可され、通常第三者の製造業者によって製造される知的財産を含んでいる建築の処理の実施である。その結果、ほとんどあらゆる腕プロセッサは少なくとも非認可された部分に関する限りでは自身の建築があると言うことができる。タケは自身の版パンダを呼ぶ。当然、遠い昔、それはにあってPCに2組のQSFPのイーサネット ポート(各刃のための1)を置き去りにする頻繁に必要な拡張の港を省略する。
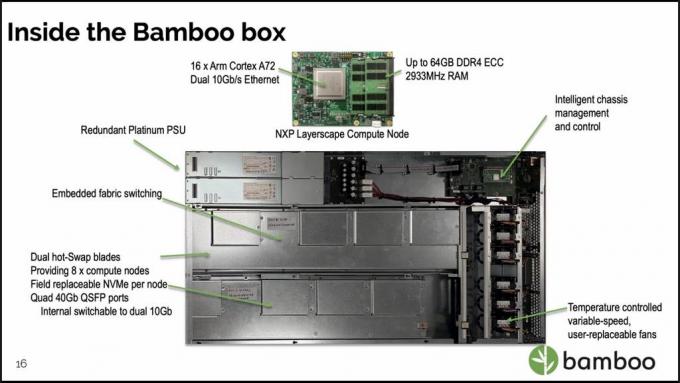
「これは多くの人々が私達のプロダクトについて理解するために努力する主要部分」是認したCraythorneをである。パンダでは、CPUはドラムおよび不揮発性メモリ(NVMe)への両方アクセスを用いる適用を、管理し、実行することに限られる。しかしネットワーキングおよび貯蔵の仕事はコプロセッサによって専ら扱われ、作り付けのネットワーク スイッチはトップの棚スイッチを取り替える。
「私達は刃の中のネットワーキングの固まりが付いているひとつひとつの刃の中のノンブロッキングL3スイッチを、「注意したディレクターSiobhan Ellisに、製品管理のタケの持っている。そうある程度は私達は刃の外のネットワーク トラフィックを送る必要はない」。オプションで、刃のQSFPの港は両方ともスイッチに接続されるかもしれないまたは1つの港はスイッチおよび刃の隣りへの他に接続されるかもしれない。「あなたが棚で」。必要とする外部スイッチの数で削減する

